안녕하세요. 엔지엠소프트웨어입니다. 오늘은 파이썬으로 간단하게 매크로를 만드는 방법에 대해 알아보도록 하겠습니다. 우선 Visual Studio Code를 실행하고, 새 파이썬 파일을 만듭니다. 저는 이전 글에서 이미 만든 test.py를 사용하도록 하겠습니다. 우선, 파이썬에서 마우스와 키보드를 제어할 수 있는 pyautogui를 설치해야 합니다. 마우스와 키보드 제어 기능뿐만 아니라 GUI에 관련된 모든 함수가 포함되어 있습니다. 이거 하나로 다 만들 수 있어요^^;
하단의 터미널에서 "pip install pyautogui"를 입력하여 설치하세요.
PS C:\Users\ngmas\Desktop> pip install pyautogui
Collecting pyautogui
Downloading PyAutoGUI-0.9.52.tar.gz (55 kB)
|████████████████████████████████| 55 kB 932 kB/s
Collecting pymsgbox
Downloading PyMsgBox-1.0.9.tar.gz (18 kB)
Installing build dependencies ... done
Getting requirements to build wheel ... done
Preparing wheel metadata ... done
Collecting PyTweening>=1.0.1
Downloading PyTweening-1.0.3.zip (15 kB)
Collecting pyscreeze>=0.1.21
Downloading PyScreeze-0.1.26.tar.gz (23 kB)
Collecting pygetwindow>=0.0.5
Downloading PyGetWindow-0.0.9.tar.gz (9.7 kB)
Collecting mouseinfo
Downloading MouseInfo-0.1.3.tar.gz (10 kB)
Collecting pyrect
Downloading PyRect-0.1.4.tar.gz (15 kB)
Collecting pyperclip
Downloading pyperclip-1.8.1.tar.gz (20 kB)
Using legacy 'setup.py install' for pyautogui, since package 'wheel' is not installed.
Using legacy 'setup.py install' for PyTweening, since package 'wheel' is not installed.
Using legacy 'setup.py install' for pyscreeze, since package 'wheel' is not installed.
Using legacy 'setup.py install' for pygetwindow, since package 'wheel' is not installed.
Using legacy 'setup.py install' for mouseinfo, since package 'wheel' is not installed.
Using legacy 'setup.py install' for pyrect, since package 'wheel' is not installed.
Using legacy 'setup.py install' for pyperclip, since package 'wheel' is not installed.
Building wheels for collected packages: pymsgbox
Building wheel for pymsgbox (PEP 517) ... done
Created wheel for pymsgbox: filename=PyMsgBox-1.0.9-py3-none-any.whl size=7420 sha256=3427b8e556242b84692d8686335557bb3aab4ac96b979de00da97f53d4d98aa0
Stored in directory: c:\users\ngmas\appdata\local\packages\pythonsoftwarefoundation.python.3.9_qbz5n2kfra8p0\localcache\local\pip\cache\wheels\7f\13\8c\584c519464297d9637f9cd29fd1dcdf55e2a2cab225c76a2db
Successfully built pymsgbox
Installing collected packages: pymsgbox, PyTweening, pyscreeze, pyrect, pygetwindow, pyperclip, mouseinfo, pyautogui
Running setup.py install for PyTweening ... done
Running setup.py install for pyscreeze ... done
Running setup.py install for pyrect ... done
Running setup.py install for pygetwindow ... done
Running setup.py install for pyperclip ... done
Running setup.py install for mouseinfo ... done
Running setup.py install for pyautogui ... done
Successfully installed PyTweening-1.0.3 mouseinfo-0.1.3 pyautogui-0.9.52 pygetwindow-0.0.9 pymsgbox-1.0.9 pyperclip-1.8.1 pyrect-0.1.4 pyscreeze-0.1.26
WARNING: You are using pip version 20.2.3; however, version 20.3.3 is available.
You should consider upgrading via the 'C:\Users\ngmas\AppData\Local\Microsoft\WindowsApps\PythonSoftwareFoundation.Python.3.9_qbz5n2kfra8p0\python.exe -m pip install --upgrade pip' command.
PS C:\Users\ngmas\Desktop>
설치가 완료되면, 몇가지 테스트를 해봅니다. 아래 코드를 입력하고, Ctrl+F5를 눌러서 모니터의 크기를 확인 해봅시다.
import pyautogui
screenWidth, screenHeight = pyautogui.size()
print('{0}, {1}'.format(screenWidth, screenHeight))
결과가 잘 나왔나요? 모니터의 해상도는 1920x1080입니다.
PS C:\Users\ngmas\Desktop> c:; cd 'c:\Users\ngmas\Desktop'; & 'python' 'c:\Users\ngmas\.vscode\extensions\ms-python.python-2020.12.424452561\pythonFiles\lib\python\debugpy\launcher' '50754' '--' 'c:\Users\ngmas\Desktop\test.py'
1920, 1080
PS C:\Users\ngmas\Desktop>
마우스의 위치를 알아볼까요?
import pyautogui
mouseX, mouseY = pyautogui.position()
print('{0}, {1}'.format(mouseX, mouseY))
정상적으로 마우스의 좌표를 가져왔습니다. 마우스 위치가 X=723, Y=269네요^^;
PS C:\Users\ngmas\Desktop> c:; cd 'c:\Users\ngmas\Desktop'; & 'python' 'c:\Users\ngmas\.vscode\extensions\ms-python.python-2020.12.424452561\pythonFiles\lib\python\debugpy\launcher' '50913' '--' 'c:\Users\ngmas\Desktop\test.py'
723, 269
PS C:\Users\ngmas\Desktop>
코드에 문제가 없는데도~ 아래와 같이 빨간줄이 그어질 수 있습니다.

pyautogui를 인식하지 못하는군요. 하지만, 실행은 잘 됩니다. VSC(Visual Studio Code)를 사용하면 많은 혜택(?)을 얻을 수 있습니다. 대표적인 기능으로 인텔리센스(자동 완성 기능)가 있죠. 대부분의 IDE가 제공하는 기능이긴하지만요. 아무튼, 상당히 좋은 기능임에도 불구하고 몇가지 버그가 존재합니다. 간혹 정상적인 코드에 빨간줄을 그어서 문제가 있는것처럼 표시합니다. 상당히 오래된 문제인데... 아직도 고쳐지지는 않았네요. 아무튼, VSC로 현존하는 대부분의 언어를 개발할 수 있다보니 캐어가 안되는 부분도 발생하는거 같아요. 그래서~ 사용자가 직접 처리할 수 있도록 해두었습니다.
- Ctrl+Shift+P
- Configure Language Specific 입력
- Python 입력
아래와 같이 settings.json 파일이 열립니다. 마지막에 python.jediEnabled:true를 추가해주세요. 그리고, VSC를 다시 실행합니다.
{
"editor.suggestSelection": "first",
"vsintellicode.modify.editor.suggestSelection": "automaticallyOverrodeDefaultValue",
"python.languageServer": "Jedi",
"python.jediEnabled":"true"
}
드디어~ 빨간줄이 사라졌네요^^

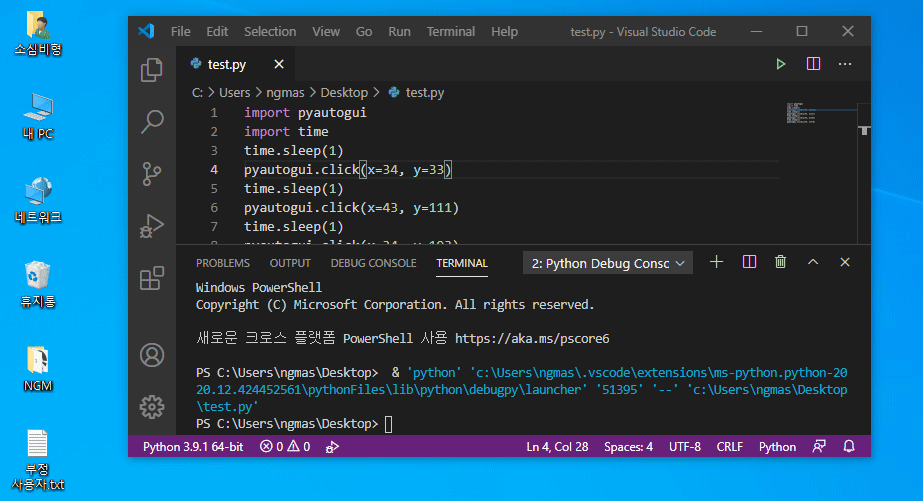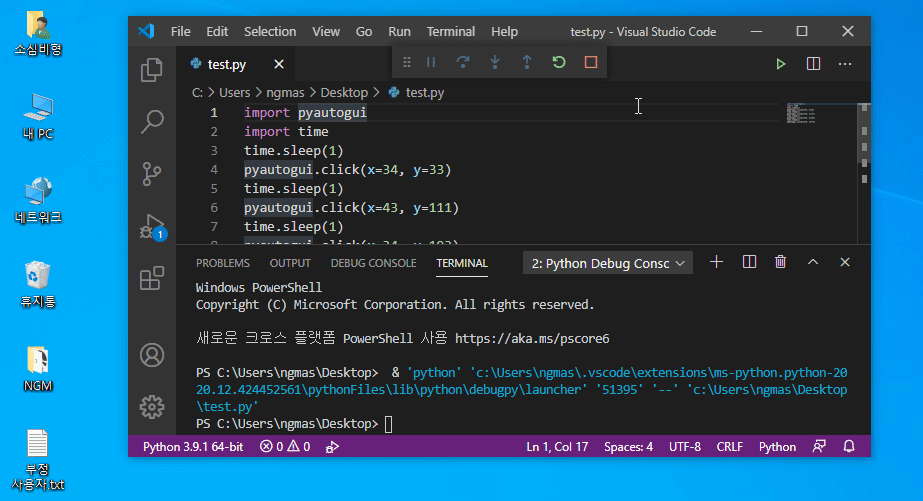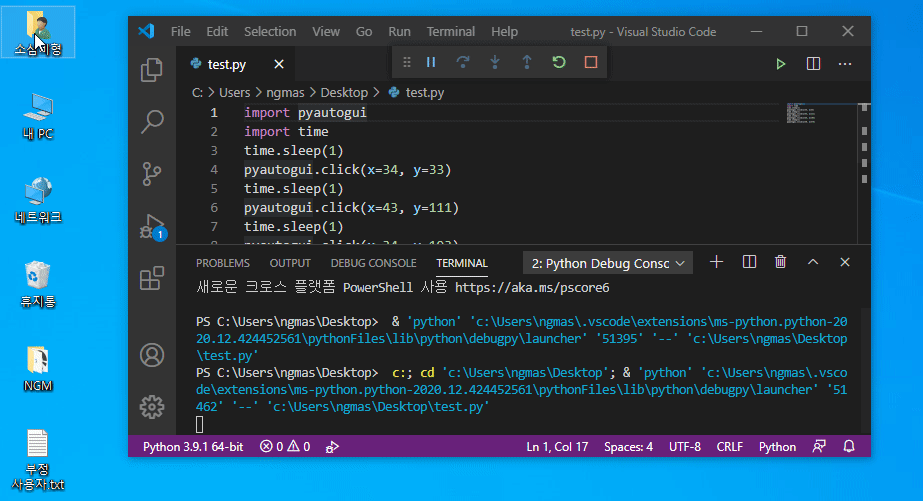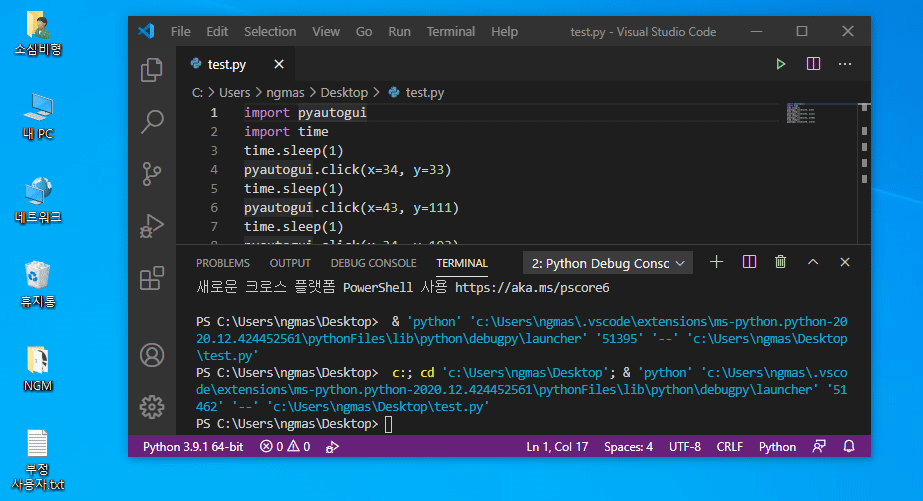
이제 간단한 매크로를 하나 만들어 볼께요~ 이 매크로는 바탕화면의 내문서(소심비형), 내 PC, 네트워크, 휴지통을 1초 간격으로 클릭하는 동작을 수행합니다.
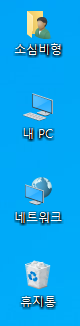
각각의 아이콘 위치를 알아내기 위해 엔지엠 에디터를 이용했습니다. 모니터 해상도가 1920x1080인 경우 각각의 위치는 아래와 같습니다.
- 내문서(소심비형) : 34, 33
- 내 PC : 43, 111
- 네트워크 : 34, 193
- 휴지통 : 36, 275
이 정보를 토대로 1초 간격으로 아이콘을 클릭하는 매크로를 만들어 볼께요. 아래 코드를 붙여넣기하고 Ctrl+F5를 눌러보세요.
import pyautogui
import time
time.sleep(1)
pyautogui.click(x=34, y=33)
time.sleep(1)
pyautogui.click(x=43, y=111)
time.sleep(1)
pyautogui.click(x=34, y=193)
time.sleep(1)
pyautogui.click(x=36, y=275)
1초 후 바탕화면의 아이콘을 순차적으로 클릭합니다.
막상 해보면~ 그리 어렵지는 않습니다. 누구나 쉽게 매크로를 만들 수 있죠^^; C, C++ C#, Java, Python을 비롯한 대부분의 언어들이 조금만 검색해보면 오픈되어 있는 소스가 많이 있습니다. 이런 소스들을 가져다가 내가 원하는 환경 및 기능으로 변경하여 사용할 수 있습니다. 처음에는 약간의 노력이 필요하겠지만 익숙해지면 누구나 1시간안에 간단한 기능들은 구현할 수 있을겁니다. 다음에는 엔지엠과 연동하는 방법에 대해 알아보도록 하겠습니다^^
출처 : http://ngmsoftware.com/bbs/board.php?bo_table=study&wr_id=241